What's New in OMNEST 5.2.1
Highlights of this release are the fine-tuning of result recording and processing (especially around weighted statistics); many bug fixes and improvements in Qtenv; makefile changes to allow DEBUG and RELEASE builds of models to co-exist, and several related changes in the IDE.
Core:
-
Figure zIndex is now additive: the effective zIndex is now the sum of the zIndex values of the figure and all its ancestors up to the root figure. This provides more flexibility, as the stacking order of figures is no longer constrained by their position in the figure tree.
-
Added cPanelFigure, a new figure type that turns off zoom for its children. cPanelFigure is handy when one needs to do relative positioning unaffected by zoom, for example when adding decorations next to submodule icons.
-
Statistics recording: added support for collecting time-weighted statistics. This is useful for variables like queue length. Add timeWeighted=1 or timeWeighted=true to a @statistic to make it collect time-weighted statistics. timeWeighted=1 affects the operation of the following filters/recorders: "mean", "stats" and "histogram". The "timeavg" recorder always computes time average; an additional recorder "avg" has also been added that always computes unweighted mean. "mean" emulates either "avg" or "timeavg", depending on the presence of the timeWeighted=1 option.
-
Changed result filters/recorders so that they interpret NaN as "missing data" and ignore it. The change affects "count" (which now also ignores nullptrs), "sum", "min", "max", "avg", "timeavg", "sumPerDuration", "stats", "histogram". For the time weighted case, NaNs mark intervals to be ignored.
-
cResultFilter: added an init() method to allow filters access the content of the @statistic property they occur in.
-
The packetBytes/packetBits filter now throw error if object is not a cPacket. They still accept (and ignore) nullptr.
-
Added support for weighted statistics to histogram classes and to cStddev (the cWeightedStddev class is no longer needed.) The primary motivation for weighted statistics is the existence of variables where time average makes much more sense than arithmetic mean, e.g. queue length.
-
The OSG viewer was factored out from Qtenv into a separate support library which is only loaded at runtime on demand. Core OMNEST no longer has any dependence on OSG or OSGEarth. This change improves simulation startup times and also debugging experience, as it eliminates the loading of the huge number of shared libraries that OSG and OSGEarth depends on. (The library loading overhead was also present in simulations that did not even contain 3D visualization.) The only API change is that one must use cOsgCanvas::EarthViewpoint instead of osgEarth::Viewpoint when using the cOsgCanvas::setEarthViewpoint().
Build:
-
opp_makemake: IMPORTANT CHANGES regarding debug/release-mode builds:
-
Models are built in RELEASE mode by default. Until now, DEBUG was the default, which resulted in casual users always running their simulations in DEBUG mode, i.e. much slower than possible.
-
RELEASE and DEBUG mode binaries can now co-exist, so users do not have to recompile when they switch modes (e.g. when they want to debug a simulation.) This is a significant gain especially for large models like INET. The goal was achieved by adding the "_dbg" suffix to the names of DEBUG-mode binaries so they don’t collide with RELEASE-mode ones.
-
Binaries are now hard-linked from the build directory (out/) to the target directory instead of being soft-linked. This leaves the copy in the build directory intact when the one in the target directory is deleted.
-
Refinements on the build process of OMNEST itself: generated files are created only once, even when using parallel build; do not copy build artifacts if not actually changed; Makefiles in the samples/ folder are re-created only if they are missing; etc.
-
The samples/ folder is now optional: deleting it in an OMNEST installation will no longer break the build.
IDE/Base:
-
The Eclipse platform was updated to the latest Oxygen milestone build (4.6.2)
IDE/Build:
-
Makefile generator: follow changes in the command-line opp_makemake tool
-
Models are built in RELEASE mode by default. Until now, DEBUG was the default, which resulted in casual users always running their simulations in DEBUG mode, i.e. much slower than possible.
-
RELEASE and DEBUG mode binaries can now co-exist, so users do not have to recompile when they switch modes (e.g. when they want to debug a simulation — remember, they are built in RELEASE mode by default.) This is a significant gain especially for large models like INET. The goal was achieved by adding the "_dbg" suffix to the names of DEBUG-mode binaries.
-
Binaries are now hard-linked from the build directory (out/) to the target directory instead of being soft-linked. This leaves the copy in the build directory intact when the one in the target directory is deleted.
IDE/Launching:
-
The Run, Profile and Debug launch types now automatically trigger build.
-
The launcher now switches the project (and optionally all projects it depends on) to the appropriate build configuration if necessary: Run and Profile will perform RELEASE build, Debug will perform DEBUG build.
-
For Debug launch, the "_dbg" suffix is added implicitly to the target name (both exe and shared lib). (The simulations will also load the "_dbg" versions of libraries when compiled to DEBUG.)
-
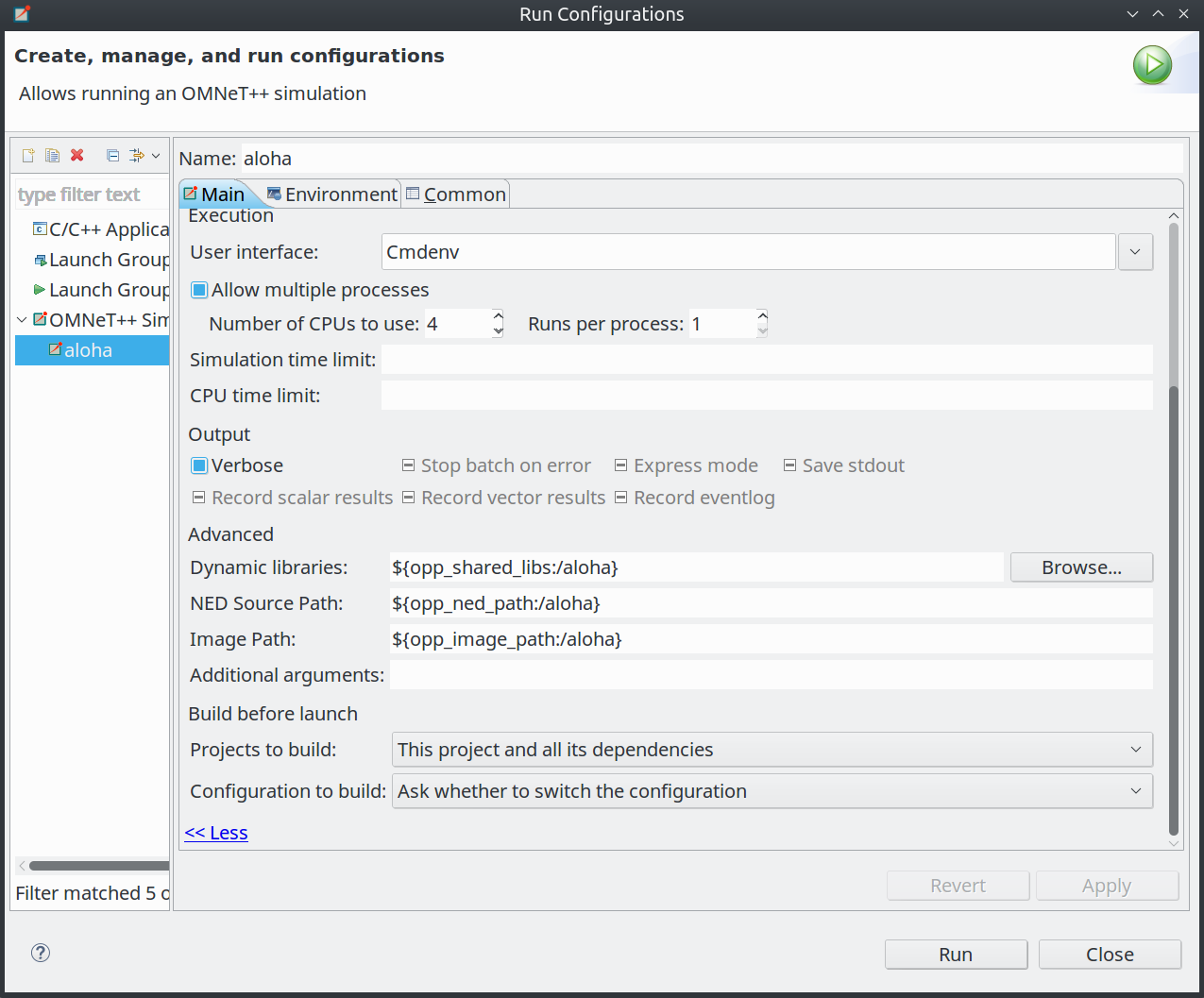
A new "Build before launch" section was added to the Launch config dialog, which allows you to control whether to switch build configuration automatically or to ask before the build. The scope of build can also configured; options are: "None", "This project", or "Project + dependencies".
-
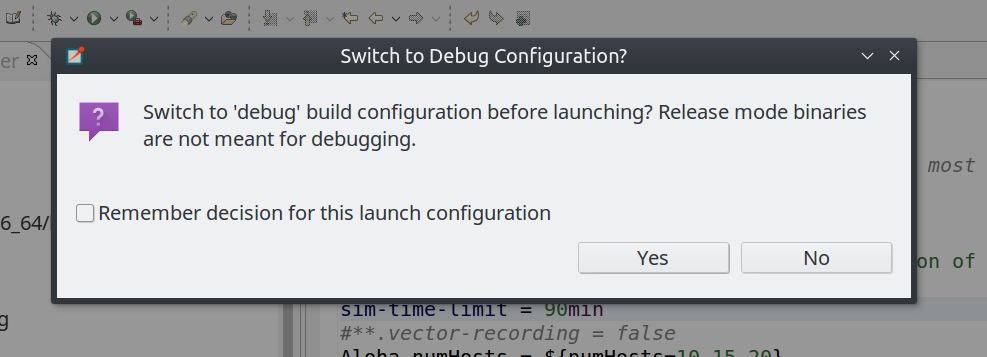
If the launch is configured as "Ask before build" (default), a confirmation dialog is shown on launch (and before the build), asking whether to switch the active build configuration to the appropriate one. The dialog allows you to set the decision as permanent and reconfigures the launch config accordingly.
-
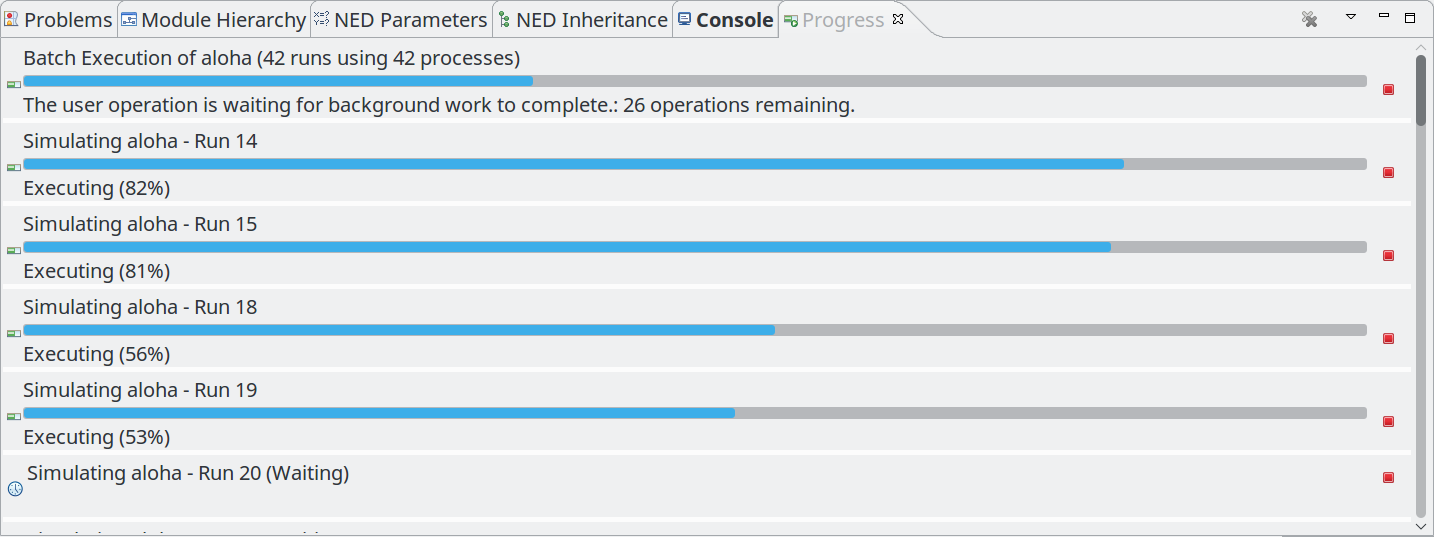
Better progress reporting and cancellation for batch runs. Internally, this is the result of switching to the new JobGroups API of Eclipse.
IDE/Analysis Tool:
-
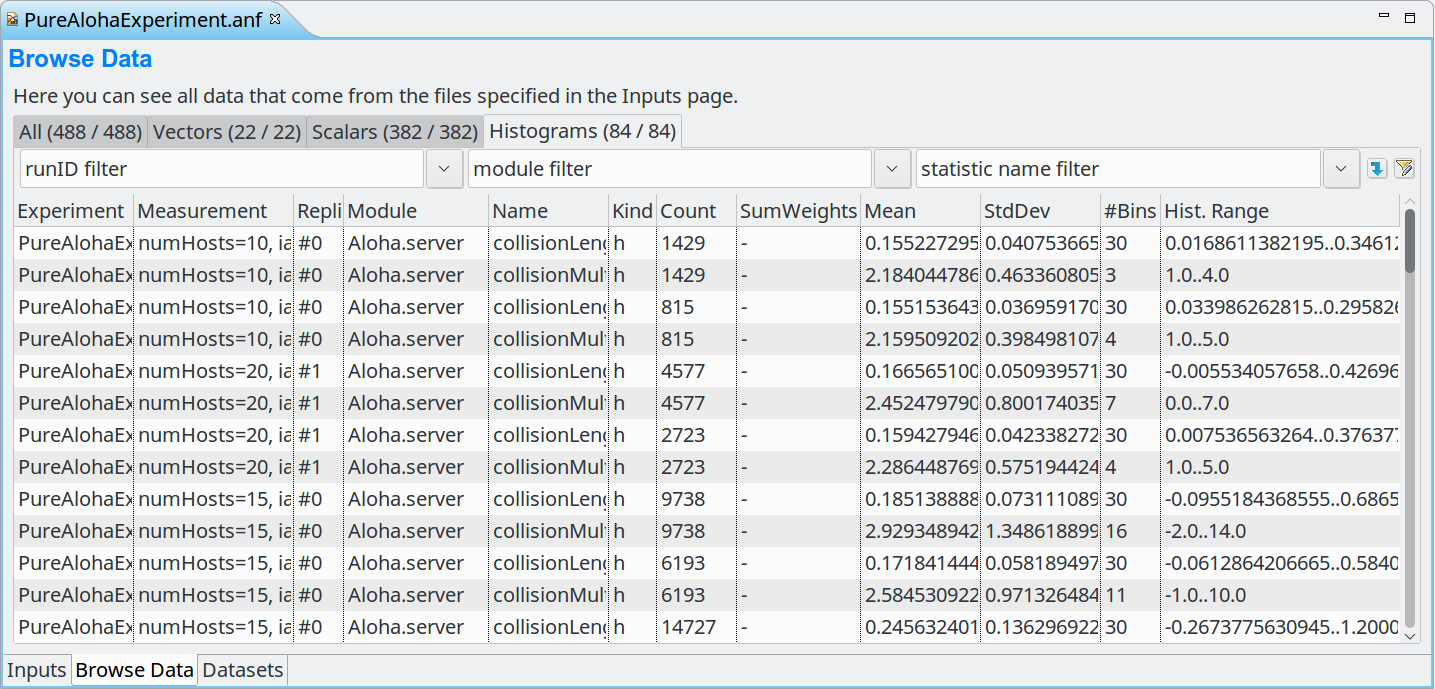
Added support for "statistic" items and for weighted statistics. Background: Specifying "record=stats" in a @statistic NED property, or or calling the record() method on a cStddDev object saves a "statistic" object in the output scalar file. A "statistic" object includes fields like the count of observations, mean, standard deviation, minimum and maximum value. "statistic" objects so far have been blown up to several unrelated scalars upon loading into the Analysis Tool. Now they are loaded as objects, and appear in the Histograms and All tabs of the Browse Data page. Statistics fields continue to be available as scalars as well, so they can be used as chart input. Also, weighted statistics (like those saved from cWeightedStddev) were not properly displayed in the Analysis Tool. This has been rectified as well. Details:
-
The Histograms tab on the Browse Data page now includes "statistics"- type results as well.
-
The Histograms tab now has new table columns: "Kind", "SumWeights", "#Bins", "Hist.Range", all displayed by default. "Kind" indicates whether a result item is a "statistic" or a "histogram", and whether it is weighted or unweighted.
-
Individual fields of "statistic" and "histogram" result items are no longer displayed on the Scalars page.
-
Properties for "statistic" and "histogram" result items now includes "Kind" ("weighted"/"unweighted") and "Sum of weights".
-
On the All tab of Browse Data page, result item fields are now in natural order (i.e. no longer alphabetically sorted).
-
-
Export dialog refined: Added "Open exported file afterwards" checkbox, better filename generation and validation, etc.
-
Changed the syntax for accessing iteration variables in filter expressions. Before, they could be accessed like run attributes, with the "attr:" prefix. Now, one needs to use the "itervar:" prefix, which is more explicit.
-
Properties view: properly display attributes, iteration variables and parameter assignments for runs
-
Better display of histogram bins in the Properties view. The display format of bins was changed from "a..b" to "[a,b)", in order to clearly indicate that "a" is inclusive and "b" is exclusive.
-
The "Variance" line has been removed from Properties view because it’s not too useful and can be easily computed as the square of the standard deviation.
-
Missing or unavailable data in table cells is now displayed with a hyphen instead of "n.a."
-
New icon for scalar items on the All tab of Browse Data page
Qtenv:
-
OSG Viewer is now a separate library, loaded at runtime.
-
Improved the appearance and usability of the Animation Parameters dialog.
-
Show (debug) or (release) in the window title based on NDEBUG.
-
Completely overhauled figure rendering. This should improve performance and fix many issues.
-
The size of arrowheads on connections and line figures is now more reasonable with many combinations of zoom level, line width, and the "zoomLineWidth" property.
-
Implemented cPanelFigure support and cumulative zIndex.
-
Figures without a tooltip inherit it from their nearest ancestor that has one. Empty strings break this inheritance, but are not shown. The own tooltip of the figure now overrides that of its associated object.
-
The special value "kind" is now also accepted as a color in the "i" tag of display strings of messages as well.
-
A large number of miscellaneous improvements, fixes and cleanups; see src/qtenv/ChangeLog.
Envir:
-
EnvirBase: changed the lifecycle of several plugin objects to per-run, i.e. those objects are now deleted and re-created between runs. Affected plugins: event log recorder, output vector file recorder, output scalar file recorder, snapshot recorder, future event set (FES). The corresponding configuration options have also become per-run options: eventlogmanager-class=, outputvectormanager-class=, outputscalarmanager-class=, snapshotmanager-class=, futureeventset-class=. Side effect: in output vector files, vector IDs now start again from 0 at the start of each run when running multiple runs. Before, they continued from where the previous run left off.
Scavetool:
-
Added --list-itervars option
-
Removed obsolete export commands 'vector' and 'scalar'
-
Do not export itervars as scalars by default; added -y, --add-itervars-as-scalars option to turn exporting itervars back on
-
Sort runs by runId, for consistent query output
-
JSON and CSV exporter changes (applies to IDE Analysis Tool as well):
-
Python export changed to JSON export with optional Python flavour
-
CSV export renamed to "CSV for spreadsheet" and significantly improved (also saves iteration variables for better run identification, etc.)
-
another CSV export added ("CSV Records"), provenly suitable as input for the read_csv() of Python Pandas
-
Result recording and processing:
-
Switch to new scalar/vector file recorders: The default values for the outputscalarmanager-class= and outputvectormanager-class= config options are now the new classes OmnetppOutputScalarManager and OmnetppOutputVectorManager. These classes rely on the new result file writer classes in common/. The old classes cIndexedFileOutVectorManager and cFileOutScalarManager still exist. They will be removed in a later version of OMNEST.
-
Save iteration variables separately from run attributes ("itervar" lines). NOTE: This changes result file format!
-
omnetpp recorders: ensure order of "param" lines in the file mirror the order in the ini file
-
Output scalar file recorders: sum and sqrSum are no longer saved for weighted statistics. This is to follow recent cStddev/cWeightedStddev change.
-
Output scalar files: do not save numeric iteration variables (of parameter studies) as scalars. Instead we’ll add them (as scalars) at load time, if needed.
-
Proper loading and exporting of weighted statistics
-
Added StatisticsResult (HistogramResult sans histogram). Until now, statistic results in scalar files were loaded as several unrelated scalars, and were not available as a single object.
-
OmnetppResultFileLoader: fix: 'run' line is mandatory since version 4.0
-
SqliteResultFileLoader: updated: histBin table was renamed to histogramBin
-
SqliteResultFileLoader: loading of vector attrs and run params was missing
-
SQLite recorder: slight changes in file format
Bugs fixed: see http://dev.omnetpp.org/bugs/changelog_page.php?project_id=1
